{kind=link}
One of the major themes here on the Science-Based Medicine (SBM) blog has been about one major shortcoming of the more commonly used evidence-based medicine paradigm (EBM) that has been in ascendance as the preferred method of evaluating clinical evidence. Specifically, as Kim Atwood (1, 2, 3, 4, 5, 6, 7, 8) has pointed out before, EBM values clinical studies above all else and devalues plausibility based on well-established basic science as one of the “lower” forms of evidence. While this sounds quite reasonable on the surface (after all, what we as physicians really want to know is whether a treatment works better than a placebo or not), it ignores one very important problem with clinical trials, namely that prior scientific probability matters. Indeed, four years ago, John Ioannidis made a bit of a splash with a paper published in JAMA entitled Contradicted and Initially Stronger Effects in Highly Cited Clinical Research and, more provocatively in PLoS Medicine, Why Most Published Research Findings Are Wrong. In his study, he examined a panel of highly cited clinical trials and determined that the results of many of them were not replicated and validated in subsequent studies. His conclusion was that a significant proportion, perhaps most, of the results of clinical trials turn out not to be true after further replication and that the likelihood of such incorrect results increases with increasing improbability of the hypothesis being tested.
Not surprisingly, CAM advocates piled onto these studies as “evidence” that clinical research is hopelessly flawed and biased, but that is not the correct interpretation. Basically, as Steve Novella and, especially, Alex Tabarrok pointed out, prior probability is critical. What Ioannidis’ research shows is that clinical trials examining highly improbable hypotheses are far more likely to produce false positive results than clinical trials examining hypotheses with a stronger basis in science. Of course, estimating prior probability can be tricky based on science. After all, if we could tell beforehand which modalities would work and which didn’t we wouldn’t need to do clinical trials, but there are modalities for which we can estimate the prior probability as being very close to zero. Not surprisingly (at least to readers of this blog), these modalities tend to be “alternative medicine” modalities. Indeed, the purest test of this phenomenon is homeopathy, which is nothing more than pure placebo, mainly because it is water. Of course, another principle that applies to clinical trials is that smaller, more preliminary studies often yield seemingly positive results that fail to hold up with repetition in larger, more rigorously designed randomized, double-blind clinical trials.
Last week, a paper was published in PLoS ONE Thomas by Thomas Pfeiffer at Harvard University and Robert Hoffmann at MIT that brings up another factor that may affect the reliability of research. Oddly enough, it is somewhat counterintuitive. Specifically, Pfeiffer and Hoffmann’s study was entitled Large-Scale Assessment of the Effect of Popularity on the Reliability of Research. In other words, the hypothesis being tested is whether the reliability of findings published in the scientific literature decreases with the popularity of a research field. Although this phenomenon is hypothesized based on theoretical reasoning, Pfeiffer and Hoffmann claim to present the first empirical evidence to support this hypothesis.
Why might more popular fields produce less reliable research? Pfeiffer and Hoffmann set up the problem in the introduction. I’m going to quote fairly generously, because they not only confirm the importance of prior probability, but put the problem into context:
Even if conducted at best possible practice, scientific research is never entirely free of errors. When testing scientific hypotheses, statistical errors inevitably lead to false findings. Results from scientific studies may occasionally support a hypothesis that is actually not true, or may fail to provide evidence for a true hypothesis. The probability at which a hypothesis is true after a certain result has been obtained (posterior probability) depends on the probabilities at which these two types of errors arise. Therefore, error probabilities, such as p-values, traditionally play a predominant role for evaluating and publishing research findings. The posterior probability of a hypothesis, however, also depends on its prior probability. Positive findings on unlikely hypotheses are more likely false positives than positive findings on likely hypotheses. Thus, not only high error rates, but also low priors of the tested hypotheses increase the frequency of false findings in the scientific literature [1], [2].
In this context, a high popularity of research topics has been argued to have a detrimental effect on the reliability of published research findings [2]. Two distinctive mechanisms have been suggested: First, in highly competitive fields there might be stronger incentives to “manufacture” positive results by, for example, modifying data or statistical tests until formal statistical significance is obtained [2]. This leads to inflated error rates for individual findings: actual error probabilities are larger than those given in the publications. We refer to this mechanism as “inflated error effect”. The second effect results from multiple independent testing of the same hypotheses by competing research groups. The more often a hypothesis is tested, the more likely a positive result is obtained and published even if the hypothesis is false. Multiple independent testing increases the fraction of false hypotheses among those hypotheses that are supported by at least one positive result. Thereby it distorts the overall picture of evidence. We refer to this mechanism as “multiple testing effect”. Putting it simple, this effect means that in hot research fields one can expect to find some positive finding for almost any claim, while this is not the case in research fields with little competition [1], [2].
The potential presence of these two effects has raised concerns about the reliability of published findings in those research fields that are characterized by error-prone tests, low priors of tested hypotheses and considerable competition. It is therefore important to analyze empirical data to quantify how strong the predicted effects actually influence scientific research.
In other words, new scientific fields are almost, by definition, full of hypotheses with low prior probabilities, because, well, it’s new science and scientists don’t have a sufficient base of research to know which hypotheses are likely to be true and which are not. I particularly like this phrase, though: “low priors of tested hypotheses and considerable competition.” Sound familiar? That’s exactly what’s going on in CAM research these days, the difference being that most CAM hypotheses are unlikely ever to become more plausible. In any case, as more and more groups start doing CAM research (multiple independent testing) and more and more literature is published on CAM, given the very low prior probability of so many CAM modalities, it is not at all surprising that there are, in essence, papers reporting positive findings in the scientific literature for pretty much any CAM claim, and we can expect the problem to get worse, at least if this hypothesis is true.
Is it true,though? Pfeiffer and Hoffmann chose a rather interesting way to test whether increasing popularity of a field results in the lower reliability of published findings in that field. They chose to look at published reports of interactions between proteins in yeast (S. cerevisiae, a common yeast used in the lab to study protein interactions, often using a system known as the yeast two-hybrid screen). The interesting aspect of this choice is that it’s not clinical research; it is far more likely to find definitive yes-no answers and validate them than it ever is in clinical research.
What Pfeiffer and Hoffmann did first was to use the text mining system iHOP to identify published interactions between proteins and genes in titles and abstracts from the PubMed database and expert-curated data from IntAct and DIP, major databases for protein interactions consisting of expert-curated interactions extracted from the scientific literature and high throughput experiments, as an additional source for published statements on protein interactions. Overall, there were 60,000 published statements examining 30,000 unique interactions. The reported frequency of each interaction was then compared to data derived from recent high throughput experiments based on yeast-two-hybrid experiments, high-throughput mass spectroscopy, tandem affinity purification, and an approach that combines mass-spectroscopy and affinity purification. The strength of this approach is that these high throughput results are not influenced by popularity because they make no a priori assumptions about the protein interactions studied and look at thousands of interactions nearly simultaneously; thus, they are not influenced by either effect being examined, the inflated error effect or multiple testing effect. The weakness of this approach is that these high throughput methods are not free from errors or bias and they do not test all the interactions that can be found in the literature. Finally, Pfeiffer and Hoffmann estimated the popularity of various proteins, or the corresponding genes that encode them, by estimating the number of times the protein or its gene is mentioned in the scientific literature, comparing the popularity of the protein interaction partners and how often the high throughput analysis confirmed interactions reported in the literature.
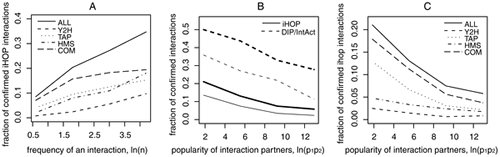
The results are summarized in this graph:
 (Click to go to original, larger image.)
(Click to go to original, larger image.)
Figure 1A shows what I consider to be a bit of a “well, duh” finding. Specifically, what it shows is that, the more frequently a specific protein interaction is reported in the literature, the more likely it is to be correlate withthe results found in the high throughput experiments, or, as the authors put it:
Interactions that are described frequently in the literature tend to be confirmed more frequently.
This is reassuring in that it at least implies that the more frequently a result is reported by independent labs, the more likely it is to be correct. After all, repetition and confirmation by other investigators are hallmarks of science. However, panels B and C, looking at both datasets examined, show a decreasing reliability for reports of protein interactions that correlates with increasing popularity of individual protein partners in the interactions. In addition, Pfeiffer and Hermann tried to look at the inflated error effect and the multiple testing effect, and found evidence for both being operative, although the evidence for a multiple testing effect was stronger than it was for the inflated error effect–ten times stronger in fact. In other words, if the results of this study are accurate, random chance acting on the testing of hypotheses with a low prior probability of being true is a far more potent force producing false positives than either fraud or “statistical significance seeking.”
So what does this mean for clinical research or, for that matter, all scientific research? First, one needs to be clear that this is a single paper and has looked at correlation. The correlation is strong, and, given the methodology used, does imply causation, although it cannot conclusively demonstrate it. What it does imply, at least from the perspective of clinical trials research, is that the more investigators doing more research on highly improbable hypotheses, the more false positives we can expect to see. Indeed, I’d love to see Pfeiffer and Hermann look at this very question.
My impression–and, let me emphasize, it is just that, an impression–is that the number of seemingly “positive” CAM studies is increasing. Certainly, it’s not unreasonable to hypothesize this to be the case, given the growth of NCCAM over the last decade, to the point where it is funding approximately $120 million a year of little but studies of low probability hypotheses. Add to that the well-known problems of publication bias and the so-called “file drawer” effect, in which positive studies are far more likely to be published and negative studies far more likely to be left in the “file drawer,” and the problem can only get worse. On the other hand, remember that this study looks only at the reliability of individual studies, not the reliability of the literature on topics in totality. The more times a result is seen in science, in general the more reliable that result will be. Similarly, the more frequently a positive result is seen in well-designed clinical studies, the more likely it is to be true. That’s why it’s so important to look at the totality of the scientific literature; the problem is, of course, winnowing out the huge number of crap studies from that totality. All Pfeiffer and Hermann’s work does, at least for me, is to provide evidence supporting a phenomenon that most researchers intuitively suspect to be true.
Whether that’s confirmation bias or real evidence that it is true will await further study.
REFERENCES:
- Ioannidis, J. (2005). Why Most Published Research Findings Are False PLoS Medicine, 2 (8) DOI: 10.1371/journal.pmed.0020124.
- Pfeiffer, T., & Hoffmann, R. (2009). Large-Scale Assessment of the Effect of Popularity on the Reliability of Research PLoS ONE, 4 (6) DOI: 10.1371/journal.pone.0005996