Tag: p-value

Is There a Replication Crisis?
The true causes and implications of the replication problem in science.
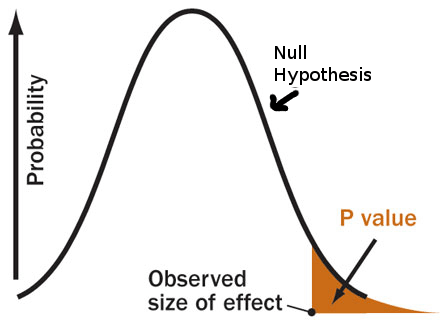
0.05 or 0.005? P-value Wars Continue
The p-value is under fire yet again, but this time with some quick-and-dirty solutions (and some long-and-onerous ones too) to the problems created by relying on this quick-and-dirty test.
P Value Under Fire
The greatest strength of science is that it is self-critical. Scientists are not only critical of specific claims and the evidence for those claims, but they are critical of the process of science itself. That criticism is constructive – it is designed to make the process better, more efficient, and more reliable. One aspect of the process of science that has received...
Psychology Journal Bans Significance Testing
This is perhaps the first real crack in the wall for the almost-universal use of the null hypothesis significance testing procedure (NHSTP). The journal, Basic and Applied Social Psychology (BASP), has banned the use of NHSTP and related statistical procedures from their journal. They previously had stated that use of these statistical methods was no longer required but can be optional included....

Beware The P-Value
The p-value was meant to be used as a convenient and quick test to evaluate how likely a result was due to chance, or a real effect. It has since come to be treated as an indication of importance or truth, particularly in the CAM world. This is a problem.
5 out of 4 Americans Do Not Understand Statistics
Ed: Doctors say he’s got a 50/50 chance at living. Frank: Well there’s only a 10% chance of that Naked Gun There are several motivations for choosing a topic about which to write. One is to educate others about a topic about which I am expert. Another motivation is amusement; some posts I write solely for the glee I experience in deconstructing...
Acupuncture, the P-Value Fallacy, and Honesty
Credibility alert: the following post contains assertions and speculations by yours truly that are subject to, er, different interpretations by those who actually know what the hell they’re talking about when it comes to statistics. With hat in hand, I thank reader BKsea for calling attention to some of them. I have changed some of the wording—competently, I hope—so as not to...
Prior Probability: the Dirty Little Secret of “Evidence-Based Alternative Medicine”—Continued
This is an addendum to my previous entry on Bayesian statistics for clinical research.† After that posting, a few comments made it clear that I needed to add some words about estimating prior probabilities of therapeutic hypotheses. This is a huge topic that I will discuss briefly. In that, happily, I am abetted by my own ignorance. Thus I apologize in advance for simplistic or incomplete...