{kind=link}
This is the second blog post about a recent PLOS One review claiming that alternative therapies such as acupuncture are as effective as antidepressants and psychotherapy for depression. The article gives a message to depressed consumers that they should consider alternative therapies as a treatment option because they are just as effective as conventional treatments. It gives promoters of alternative therapies a boost with apparent evidence from a peer-reviewed journal that can be used to advertise their treatment and to persuade third-party payers that alternative treatments are just as effective as antidepressants and should be reimbursed.
In my first post, I could not reconcile what was said in this article with the citations that it provided. The authors also failed to cite some of their own recent work where it would have been embarrassing to arguments they made in the review. Most importantly, other meta-analyses and systematic reviews had raised such serious concerns about the quality of the acupuncture literature that they concluded that any evaluation of its effectiveness for depression would be premature
I will show in this blog post that the review article is misleading junk science, but that it also demonstrates the need for PLOS journals to publish citable critiques when they inevitably have let bad articles be published. Editorial oversight and prepublication review can never be perfect, but lapses in quality should be correctable in citable articles with the same status as the work they are correcting. Readers who find junk science in PLOS should not be left with the only options of blogging or commenting in a thread that requires handsearching to find, as they are now.
I will be criticizing the review for not providing readers with a means of independently evaluating what was being claimed, the idiosyncratic use of common terms that typically mean something else in other contexts, the unorthodox analyses integrating data across studies with voodoo statistics, and the ideologically driven conclusions. Having read and re-read the article numerous times, I can find no better critique that what Don Klein said of an earlier article by one of the review article’s authors, Irving Kirsch:
a miniscule group of unrepresentative, inconsistently and erroneously selected articles arbitrarily analyzed by an obscure, misleading effect size
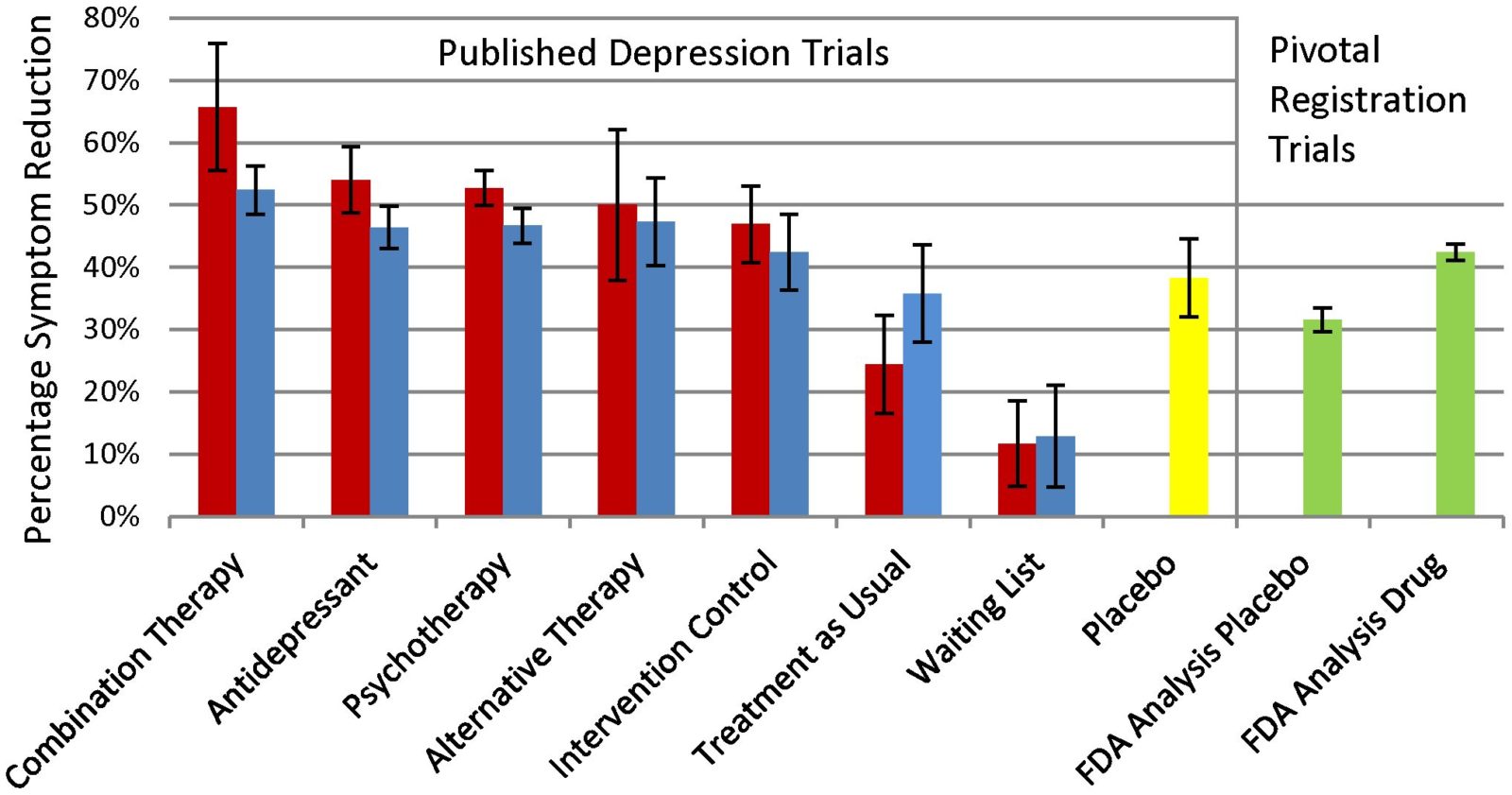
The article lacks transparency in not providing the basic background and data that one needs to interpret a systematic review and should expect to find there. Quantitative data for statements in the abstract and discussion sections are largely missing from the results section, except for what is presented in a bar graph claiming to make comparisons among 10 possible treatment and control conditions. But just try to figure out from the article which studies of what treatments went into constructing the bars.

Trust our authority, we did a systematic review.
Playing sleuth with obscure and misleading clues
I thought I knew was meant by “alternative treatments” because the introduction stated simply “alternative treatments such as acupuncture and exercise” and the method section said “we conducted a similar search for controlled trials of alternative therapies (exercise and acupuncture) for depression.” I couldn’t find any further formal definition of alternative treatments for the rest of the article.
However, when I accessed appendix S2 (I wonder how many readers actually go to the trouble of doing this), I found that the alternative therapies evaluated in combination with antidepressants for the “combination therapy” bar in the graph included sham acupuncture (1 study), verum acupuncture (1), brief dynamic therapy (1), nurse led problem-solving (1), social skills training (1), relaxation training (2), and one cognitive behavioral session plus task assignment (1). This appendix also noted that the treatments that went into the bar graph as “alternative therapies” were aerobic training (3), autogenic training (1), exercise (8), running (2), acupuncture (3), and laser acupuncture (1). Active intervention control groups included acupuncture control (3) bright light therapy (1), inactive laser acupuncture [what’s that?] (1), low intensity stretching (1) massage therapy (1), relaxation training (2), and weightlifting (1). These were further lumped together with 16 other conditions including bibliotherapy, counseling, client centered therapy, parenting education, brief cognitive therapy, and marital therapy in order to form the “active intervention controls” group summarized in the another bar in the graph.
Some of this mixed bag of “active intervention control groups” are evidence supported therapies for depression, others are evidence supported, but not for depression, and others are simply untested or unproven treatments lacking a scientific rationale. But they are all simply lumped together in a single summary statistic.
The text of the article gave no citations for which study provided what treatment, so I went to Appendix S1 where all of the 115 treatment trials included in the analysis were listed (Again, who would bother to do this? Figuring out what-is-being-said-about-what should not be so difficult.) I could not consistently tell simply from the titles which articles evaluated which of these treatments or provided which control group or when acupuncture was being considered an active treatment or an active control.
There were only five acupuncture studies listed and so I looked them up. Three were from a single American research group, two from China. All were methodologically flawed, underpowered studies explicitly labeled as preliminary or exploratory. Only one involved antidepressants and only combined with acupuncture. None involved a test of acupuncture against psychotherapy. With no head to head comparisons provided by these studies, I do not understand why these authors did not give up and simply declare that there was insufficient quality literature for a comparison of acupuncture versus antidepressants or psychotherapy. Instead, the authors continued undeterred with their integration and meta analysis. I guess that they had a conclusion to get to.
The legend for the bar graph indicates the results for unblinded treatments are in red and blinded treatments are in blue. Try to figure out what is meant by “blinded,” because it is probably not what you came to the article expecting. Investigators evaluating psychotherapy are faced with the problem that their raters of outcomes might be biased if they knew which treatment patients had been receiving. Trials are commonly considered blinded if the raters do not know what treatment patients got, or if evaluations of outcome came directly from patients. There is evidence that patient self-report is actually a conservative means of evaluating interventions for depression, relative to interviewer ratings.
In contrast, this review considered ratings coming directly from patients as unblinded, i.e., inferior, and lumped self-report with results obtained in studies where raters who knew to which treatments patients they were assigned. There is no way of unpacking the studies considered unblinded because of patient self-reported outcomes versus those considered unblinded by the usual definition. So there is no way of comparing the results of this review with the existing literature. Readers relying on their familiarity with the psychotherapy literature to interpret these results will be misled.
A meta-analysis by any other name….
The article had already gotten off to a bad start with the title and abstract identifying it as a systematic review, but not labeling it as a meta-analysis. I had a lively debate with colleagues about whether this article can even be considered a meta-analysis. We all agreed that it violates basic rules in conducting and reporting a meta-analysis and would yield unreliable results.
My opinion is that the systematic review is a meta-analysis because it involves integrating and analyzing results from different clinical trials (therefore, meta-analyzing). There are established ways for systematically amassing and integrating data from clinical trials and well-known problems when alternative methods are used. Authors should not escape from these standards by simply failing to call their work a meta-analysis. The authors of the present “systematic review” should know better, because three of them have published peer-reviewed meta-analysis.
Meta-analyses are supposed to be the new gold standard for evaluating evidence from clinical trials. Best evidence was once the blinded randomized controlled trial, but such trials are often methodologically flawed and inconsistent in the results, and the failure of positive results to replicate is notorious. Meta-analysis supposedly holds the promise of being able to integrate data from across trials in ways that overcome the flaws of individual trials and resolves the apparent contradictions in their results.
But investigators conducting meta-analysis are often arbitrary in deciding what trials are included, how differences in their individual quality are taken into account, and how the various trials are lumped or split in integrating a set of trials and arriving at an overall interpretation. The ability of readers to determine exactly what was done and to evaluate for themselves whether conclusions are appropriate depends on authors adhering to standards with at least a minimal level of transparency. Authors must give readers enough information to decide for themselves. In the case of this article, Caveat Lector, unless you are willing to simply accept the authors’ sometimes outrageous claims, you going to have to either simply dismiss them or take the time to do your own literature search without much help from what is presented in this article.
A standard for evaluating meta-analyses and systematic reviews
The ‘Assessment of Multiple Systematic Reviews’ (AMSTAR) is a brief validated checklist for evaluating meta-analyses and systematic reviews, and can be accessed here. Following the numbering of the AMSTAR items, the article is flawed in in the following ways if:
3. Was a comprehensive literature search performed? The article claims there was a comprehensive search of the literature and even provides a flow chart of searches. But I could not map the flow of searches into the small number of articles ultimately included in the analyses, as seen in numbers in Appendix S2. And things were otherwise confused and confusing. The citations included in the text for the first search column indicates that the search largely overlapped with the searched indicated in the second column. Different search strategies were used for exercise and acupuncture than for psychotherapy. The authors started only with a Cochrane Collaboration review of exercise for depression and a Cochrane Collaboration review of acupuncture for depression, ignoring other meta-analysis of these treatments. In contrast, the author searched the literature for meta-analyses of psychotherapy and drew on them for studies to be included in their review.
5. There was no list of excluded studies. Readers are thus not in a position to evaluate whether the exclusion was appropriate and therefore whether the meta-analysis is balanced or biased. Obviously, lots of studies were excluded, but we are given no reason why. For instance, the flow chart says the authors started with an updated Cochrane Collaboration review of acupuncture and depression. I checked and found that Cochrane Collaboration review identified 41 trials and retained 30 for meta-analysis. Are we to believe that in only retaining five acupuncture studies , these authors of this review were wiser and had stricter standards than the Cochrane group? Maybe, but that should require some explaining.
Usually, peer reviewers insist on a table of excluded studies, and with an open access, internet journal, there is no worry about page limitations restricting what can be provided to readers.
6. Basic characteristics of the included studies were not provided. These data are critical for a reader to be able to evaluate the appropriateness of inclusion, as well as getting a clinical sense of the appropriateness of lumping or splitting studies for analyses. Again, why didn’t the PLOS One editor or peer reviewers insist on this?
7. There was no assessment of the scientific quality of the included studies. The authors note that some of the results included in the meta-analyses were limited to patients who completed the trial (but they do not say which or how many), while other studies were intention-to-treat analyses, i.e., all patients who were randomized included, regardless of whether they were full exposure to the treatment.
Consider this: it is meaningful information that substantial numbers of patients assigned to a treatment are not around to be assessed at the end of treatment. Not being available for follow up assessment is seldom random, and often occurs because of dissatisfaction with the treatment received. The purpose of a randomized trial is thus defeated if only data from completers are analyzed. Intention to treat analyses are the gold standard and we could expect that trials that did not rely on them were biased, and perhaps by other methodological flaws.
The scientific quality of included studies varied, depending on whether they were evaluations of alternative treatments like acupuncture versus antidepressants or psychotherapy. I already noted the poor quality of the acupuncture studies, as the Cochrane Collaboration and others have done. In contrast, the FDA Registry of antidepressant trials has rather strict methodological requirements, and so these trials should be of better quality, particularly after unpublished trials were accessed, as these authors did. To investigate the issue of systematic variability in the quality of trials being considered, I took another quick look at the titles of psychotherapy studies listed in Appendix S2.
Some appeared not even to be the main reports of a clinical trial, but post hoc secondary analyses. A number of the titles indicated that the studies were preliminary, exploratory, or pilot studies. Anyone familiar with the psychotherapy literature knows the authors often so label their studies after the fact, especially when something has gone wrong so they were unable to complete the study as planned or when they want to pass off statistically improbable positive findings from an underpowered study as valid. So, we need to keep in mind that type of intervention being evaluated is probably confounded with quality and bias in ways we really can’t readily disentangle.
8. The article’s provocatively stated conclusions did not take into account the scientific quality of research that was reviewed. It’s appropriate to qualify conclusions of systematic reviews and meta-analyses with acknowledgment of the limitations to the quantity and quality of available studies. For instance, it’s common for Cochrane reviews to declare that the quality of studies is insufficient to decide if an intervention is effective, as was the case in the updated Cochrane review from acupuncture. In contrast, authors of this review boldly and confidently stated conclusions when there are ample reasons to be skeptical and even to avoid yet making any conclusions.
9. Combining the findings of studies was patently inappropriate and there was no test of whether it should have been done. There was no quantitative evaluation of whether it was statistically appropriate to combine studies (statistical heterogeneity) nor consideration of whether the specific lumping of studies and conditions made sense clinically (clinical heterogeneity). As we saw, lots of questions could be raised about the lumping and splitting, particularly in the creation of the group of active intervention control conditions, which don’t at all seem to belong together.
10. There was no conventional assessment of publication bias, yet based on the past systematic reviews I covered in my last post, there was good reason to suspect rampant publication bias.
Combining results from different clinical trials
The authors’ strategy for abstracting results from different trials was flawed, produced biased results, and, like other aspects of this article, should have been caught by the PLOS editor and reviewers.
The standard way of summarizing results from trials is to calculate pre-post differences for the contrasting groups, take the difference in change between the groups, and standardize it. So, we calculate how much patients in the intervention group changed, how much patients in the control group changed, the difference between the two groups, and then standardize this so that results have the same metric and can be combined with results of other trials.
Think of it: We might expect the results for interventions to vary with the trial in which they were evaluated, depending on how depressed the sample of patients were that was being studied and whether results for all patients who had been randomized were analyzed. We also should expect differences in the performance of antidepressants whether the drugs are administered in a trial advertised as recruiting patients for a comparison of antidepressants versus psychotherapy versus a trial advertised as comparing antidepressants versus acupuncture. Patient characteristics including their preferences and expectations matter. These are just some of many contextual factors that might influence the differences in effects that are found.
Thus, treatments do not have effect sizes, only comparisons of treatments do, and analyses have to take into account that the differences that occur are nested within trials and vary across trials. And the assumption that a set of trials are sufficiently similar in their results to be combined can be examined with statistical tests of heterogeneity—whether results of studies taken to be similar are sufficiently homogeneous or, if they are too different—heterogeneous–what the source of this heterogeneity might be. The conclusion of many meta analysis is that results observed in a set of trials are too variable for the results to be meaningfully integrated.
So, if authors intend to lump under the heading “combination treatment,” antidepressants plus acupuncture, antidepressants plus nurse delivered problem-solving, and antidepressants plus relaxation training, they are assuming that these are all equally representative of alternative treatment and results from them being added together generalize back to the individual treatments. In conventional meta analysis, whether this is reasonable can be tested, but it was not in this review.
What the authors did was radically different, simple, but nonsensical. They calculated standardized pre-post differences for each intervention separately and then averaged them into the numbers for the groups represented in the bar graph. They thus compared summary effects of particular broad groups of treatment to each other and to various lumpings of control conditions. I have never seen this done except in other meta-analyses conducted by one of the authors, Irving Kirsch, and he routinely gets roundly criticized for his idiosyncratic method. Critics have noted that this method produces different results than the conventional method applied to the same data.
The authors’ method of calculating the effects of treatments ripped the treatments from the context in clinical trials and ignored all differences among those trials. They considered the treatments going into a group as if they were equivalent, and then made comparisons with other treatments and control groups. If the authors approach were valid, we would not even need to conduct randomized clinical trials. Rather all we would have to do is simply recruit groups of patients, expose them to treatments, and collect and compile the results.
The authors also ignored whether the comparisons they were making were head-to-head, i.e, actually occurred in the clinical trials, or were indirect, artificially constructed by comparing the results for treatments from very different trials. There is ample evidence that head-to-head comparisons are more valid.
In summary, the authors conclude that antidepressants and psychotherapy were not significantly more effective than alternative therapies such as acupuncture and exercise or even active control conditions. They arrived at this conclusion having only one flawed preliminary study from China comparing acupuncture to antidepressants and no comparisons between acupuncture and psychotherapy. They arrived at this conclusion when other meta-analyses were concluded that the poor quality of the existing acupuncture literature for depression did not allow any statements about its efficacy and when other meta-analyses of exercise for depression were concluding that it had at best short-term effects. A recent large-scale study failed to find effects of exercise for depression.
[I think an evidence-based case could be made for exercise as the first step in a stepped care approach to mildly and moderately depressed persons, or maybe the first step in a stepped diagnosis of persons who are having mood problems. If they recover and their improved mood continues, then a diagnosis of major depression and more intensive care are not appropriate. But the authors of this review are not interested such subtleties.]
They are quite impressed with their conclusions and state even more boldly
Our results also suggest the interpretation of clinical research evaluating relative efficacy of depression treatments using the randomized, double-blind paradigm is problematic. With the exception of waiting-list control and treatment-as-usual, it is difficult to differentiate active treatments from “treatment controls” in adequately designed and highly blinded trials.
Nonsense. I think that what they’ve really shown is that if one adopts idiosyncratic approaches to selecting trials and summarizing the data derived from them, one can arrive at conclusions that are quite different from more conventional syntheses of clinical trial data.
Postscript
At about the same time that this article was being accepted at PLOS One, one of its authors, Irving Kirsch was hyping in his CBS 60 Minutes News interview his conclusions from an article he had previously published in PLOS Medicine. His message was that any differences between antidepressants and pill placebo were clinically trivial. Even though the PLOS Medicine paper is among the most accessed and cited of any PLOS Medicine articles to date, the systematic review did not cite it, perhaps because of the apparent contradiction that its conclusion and the one being made in the review that antidepressants are better than pill placebo, but no better than acupuncture or exercise.
In either case, there is junk science and misleading mischief being perpetrated with the credibility of publishing in a PLOS journal attached. Kirsch’s PLOS Medicine article received lots of scathing commentary in that journal, but these are not citable nor directly accessible with electronic bibliographic databases such as ISI Web of Science or PubMed. Readers must have the persistence to get past the misleading abstract posted at these resources, go back to the actual article in the PLOS journal, and scroll down through the many comments. A number of frustrated commentators ultimately, and often much later, published extended critiques elsewhere. But readers should be able to find critiques going directly to PLOS. I think the readers of PLOS journals deserve active post-publication debate in these journals that is citable and accessible through electronic bibliographic sources. If misleading abstracts of PLOS articles appear in those electronic resources, and they inevitably will, abstracts of critiques ought to appear there also. Let readers decide which side to believe.
It’s time for PLOS journals to stop allowing themselves to be used for dissemination of junk science and propaganda without the opportunities for debate and correction. The reputation of PLOS journals is at stake.